How to use the STDEV.S function

What is the STDEV.S function?
The STDEV.S function returns standard deviation based on a sample of a population.
Table of contents
1. Introduction
What is Standard Deviation?

Standard deviation tells you how far from the average values are spread out. Both charts above have numbers and an average plotted, they share the exact same average however, the numbers are not the same.
Chart A above shows that the values are more spread out than the values in chart B. Chart A has a standard deviation of 23.45256334, standard deviation for chart B is 5.207075606. Standard deviation is fundamental in statistics.

A normal distribution is a symmetric, bell-shaped probability distribution that is commonly used in statistics and probability theory. The shape of the normal distribution is determined by its mean (μ) and standard deviation (σ). The mean represents the center of the distribution, while the standard deviation represents the spread or dispersion of the data around the mean.
- A normal distribution with a standard deviation of 0.5 is relatively narrow and tightly clustered around the mean. The values in the distribution are concentrated within a smaller range, with most values falling closer to the mean. The curve appears tall and steep, indicating a higher concentration of data points near the mean.
- A normal distribution with a standard deviation of 1 is the most commonly used normal distribution, often referred to as the standard normal distribution. The standard deviation of 1 represents a moderate spread of the data around the mean. About 68% of the data falls within one standard deviation (±1σ) of the mean, and approximately 95% of the data falls within two standard deviations (±2σ) of the mean. The curve has a characteristic bell shape, with a smooth and gradual taper towards the tails.
- A normal distribution with a standard deviation of 2 is relatively wide and spread out compared to the standard normal distribution. The data is dispersed over a larger range, with values more spread out from the mean. The curve appears shorter and flatter, indicating a lower concentration of data points near the mean.
What is the difference between the STDEV.P function and the STDEV.S function?
STDEV.P function calculates the standard deviation for a population and the STDEV.S function calculates the standard deviation for a sample. STDEV.P uses the count of all values (n) in the denominator.
STDEV.S uses (n-1) in the denominator (Bessel's correction). This accounts for the difference between sample variance and population variance in statistics. STDEV.S is better for sample inferential statistics.
STDEV.P math formula:

STDEV.S math formula:
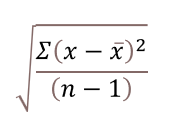
When to use the STDEV.P function and the STDEV.S function?
Use STDEV.P if you have the full population data. Use STDEV.S if you have a sample of limited data from a larger population. STDEV.P will result in a lower standard deviation compared to STDEV.S on the same data.
Sample standard deviation is considered a better estimate for inferring population parameters.
What is inferring population parameters?
Population parameters refer to the actual values of statistics that describe an entire population, such as the population mean or standard deviation. However, the true population parameter values are often not known.
What is sample inferential statistics?
Sample inferential statistics are methods that allow using statistics calculated on a sample of data to infer the unknown population parameters.
For example:
- The sample mean can be used to estimate the population mean.
- The sample standard deviation can estimate the population standard deviation.
How can standard deviation be used to find outliers?
Standard deviation can be used to identify potential outliers in a dataset by defining a range based on the mean and standard deviation values. Observations that fall outside this range are considered outliers.
A common approach is to use the range μ ± 3σ, which covers approximately 99.7% of the data points if the distribution is normal.
Values below (μ - 3σ) are considered potential lower outliers.
Values above (μ + 3σ) are considered potential upper outliers.
μ - the mean
σ - standard deviation
What is the 68–95–99.7 rule?
The 68–95–99.7 rule, also known as the Empirical Rule, is a useful statistical principle that describes the percentage of data values that fall within certain standard deviations from the mean in a normal distribution.
- 68% of the data falls between μ ± 1σ
- 95% of the data falls between μ ± 2σ
- 99.7% of the data falls between μ ± 3σ
It's important to note that the 68–95–99.7 rule is an approximation and assumes that the data follows a normal distribution. In cases of skewed or heavy-tailed distributions the percentages may not hold true. Alternative methods may be needed to describe the data spread accurately.
2. Syntax
STDEV.S(number1, [number2], ...)
3. Arguments
| number1 | Required. The first number argument that represents a sample of the population. |
| [number2] | Optional. Up to 253 additional number arguments. |
The STDEV.S function ignores logical values and text values.
For large sample sizes, STDEV.S and STDEV.P return approximately equal outputs.
4. Example
A software engineer has measured app usage based on metrics from a group of users. Assume the data follows a normal distribution. Find the outliers outside the 2 standard deviations (±2σ) range?
The data is:
| App usage |
| 66 |
| 88 |
| 102 |
| 109 |
| 114 |
| 109 |
| 103 |
| 106 |
| 89 |
| 100 |
The argument is:
number1 = B16:B25
The data points are specified in cells B16:B25 in the image above.
The image above shows a chart containing a blue curve representing the probability mass function of a normal distribution where the mean is 99 and the standard deviation is 14.18, calculated below. The chart shows the standard deviations denoted ±1σ, ±2σ, and ±3σ, cells E19:E20 display ±2σ standard deviation. 2σ = 70.25 and -2σ = 126.95
Formula in cell E15:
Cell E15 displays 14.18 which represents the standard deviation (σ) based on the values in B15:B25. We can use this value and the arithmetic mean to calculate the ±2σ standard deviations.
Formula in cell E19:
The formula in cell E19 first calculates the arithmetic mean using the AVERAGE function. It then takes this mean value and subtracts twice the standard deviation from it. Specifically, it subtracts the product of 14.18 and 2 from 99, resulting in a value of 70.25.
99 - (14.175 × 2) = 98.6 - 28.35 = 70.25
Formula in cell E20:
The formula in cell E20 uses the AVERAGE function to calculate the arithmetic mean then calculates the total with the standard deviation multiplied by 2.
99 + (14.18 × 2) = 98.6 + 28.35 = 126.95
The chart in the image above shows a normal distribution with the standard deviations denoted ±1σ, ±2σ, and ±3σ. One data point is outside the ±2σ standard deviations which is 66.
5. How is the function calculated?
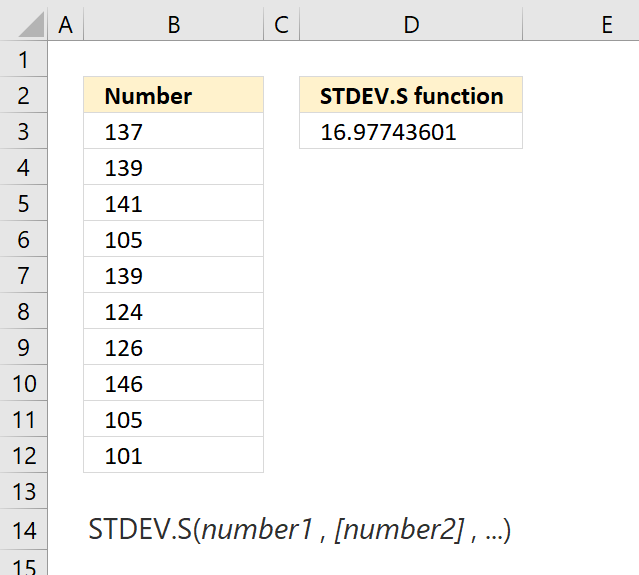
This example demonstrates how to manually calculate the standard deviation based on a sample. The image above shows data points in cell range B3:B12, the calculation is in cell D3. Here is the data:
| Number |
| 137 |
| 139 |
| 141 |
| 105 |
| 139 |
| 124 |
| 126 |
| 146 |
| 105 |
| 101 |
The math formula behind the calculation in cell D3 is:
√(Σ(x-x̄)2/(n-1))
- x is each value
- x ̅ is the average of all values
- n is the number of values
Formula in cell D3:
Explaining the math formula
Here is the math formula Excel uses for calculating the standard deviation for a sample size:
x is each value
x ̅ is the average of all values
n is the number of values
Step 1 - Calculate the average
The arithmetic mean is calculated by adding all the values in a dataset and then dividing by the total number of values.
137+139+141+105+139+124+126+146+105+101 equals 1263.
1263/10 equals 126.3
Step 2 - Subtract the average from each value
137-126.3 = 10.7
139-126.3 = 12.7
141-126.3 = 14.7
105-126.3 = 21.3
139-126.3 = 12.7
124-126.3 = -2.3
126-126.3 = -0.3
146-126.3 = 19.7
105-126.3 = -21.3
101-126.3 = 25.3
Step 3 - Calculate the square
10.72 = 114.49
12.72 = 161.29
14.72 = 216.09
(-21.3)2 = 453.69
12.72 = 161.29
(-2.3)2 = 5.29
(-0.3)2 = 0.09
19.72 = 388.09
(-21.3)2 = 453.69
(-25.3)2 = 640.09
Step 4 - Sum numbers
114.49+161.29+216.09+453.69+161.29+5.29+0.09+388.09+453.69+640.09 equals 2594.1
Step 5 - Divide sum by count minus 1
2594.1/(10-1)
becomes
2594.1/9
equals
288.233333333333
Step 6 - Calculate the square root
288.233333333333^(1/2) equals 16.9774360058677
6. Sort rows by sample standard deviation

The image above shows a formula in cell B8 that sorts rows from cell range B3:N6 by the standard deviation of a sample from large to small. Column P contains these measures.
Here is the data:
| Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec | |
| North | 364 | 289 | 828 | 258 | 64 | 339 | 443 | 53 | 58 | 448 | 64 | 384 |
| South | 165 | 715 | 12 | 787 | 884 | 644 | 753 | 571 | 398 | 159 | 839 | 351 |
| East | 143 | 136 | 361 | 506 | 959 | 205 | 298 | 134 | 768 | 364 | 93 | 889 |
| West | 907 | 672 | 900 | 935 | 598 | 918 | 775 | 517 | 530 | 387 | 347 | 796 |
Formula in cell B8:
The formula returns the rows sorted based on the standard deviation calculated per row. Here is the output from that operation:
| East | 143 | 136 | 361 | 506 | 959 | 205 | 298 | 134 | 768 | 364 | 93 | 889 |
| South | 165 | 715 | 12 | 787 | 884 | 644 | 753 | 571 | 398 | 159 | 839 | 351 |
| North | 364 | 289 | 828 | 258 | 64 | 339 | 443 | 53 | 58 | 448 | 64 | 384 |
| West | 907 | 672 | 900 | 935 | 598 | 918 | 775 | 517 | 530 | 387 | 347 | 796 |
The Excel 365 formula spills values to cells below and to the right as far as needed, this is called spilling. A #SPILL! error occurs when at least one of the destination cells is non-empty.
Explaining formula
Step 1 - Calculate the standard deviation of a sample
STDEV.S(a)
Step 2 - Build the LAMBDA function
The LAMBDA function build custom functions without VBA, macros or javascript.
Function syntax: LAMBDA([parameter1, parameter2, …,] calculation)
LAMBDA(a,STDEV.S(a))
Step 3 - Calculate the standard deviation of a sample by row
The BYROW function puts values from an array into a LAMBDA function row-wise.
Function syntax: BYROW(array, lambda(array, calculation))
BYROW(C3:N6,LAMBDA(a,STDEV.S(a)))
returns
{226.967091460548; 297.500445632465; 308.956699918035; 212.224937842904}
Step 4 - Sort rows based on the standard deviation of a sample
The SORTBY function sorts a cell range or array based on values in a corresponding range or array.
Function syntax: SORTBY(array, by_array1, [sort_order1], [by_array2, sort_order2],…)
SORTBY(B3:N6,BYROW(C3:N6,LAMBDA(a,STDEV.S(a))),-1)
becomes
SORTBY(B3:N6,{226.967091460548; 297.500445632465; 308.956699918035; 212.224937842904},-1)
and returns

7. Function not working
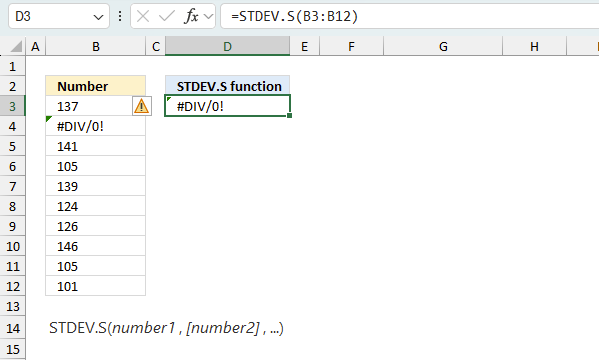
The STDEV.S function returns
- #NAME? error if you misspell the function name.
- propagates errors, meaning that if the input contains an error (e.g., #VALUE!, #REF!, #N/A), the function will return the same error.
7.1 Troubleshooting the error value
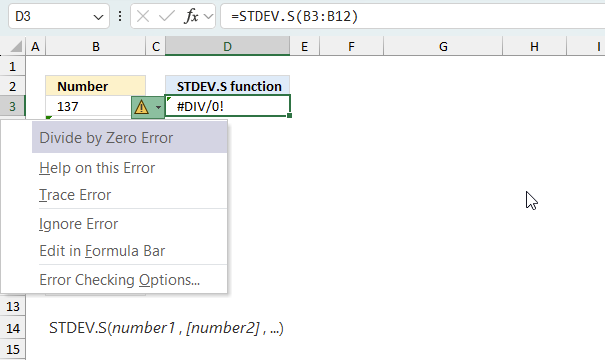
When you encounter an error value in a cell a warning symbol appears, displayed in the image above. Press with mouse on it to see a pop-up menu that lets you get more information about the error.
- The first line describes the error if you press with left mouse button on it.
- The second line opens a pane that explains the error in greater detail.
- The third line takes you to the "Evaluate Formula" tool, a dialog box appears allowing you to examine the formula in greater detail.
- This line lets you ignore the error value meaning the warning icon disappears, however, the error is still in the cell.
- The fifth line lets you edit the formula in the Formula bar.
- The sixth line opens the Excel settings so you can adjust the Error Checking Options.
Here are a few of the most common Excel errors you may encounter.
#NULL error - This error occurs most often if you by mistake use a space character in a formula where it shouldn't be. Excel interprets a space character as an intersection operator. If the ranges don't intersect an #NULL error is returned. The #NULL! error occurs when a formula attempts to calculate the intersection of two ranges that do not actually intersect. This can happen when the wrong range operator is used in the formula, or when the intersection operator (represented by a space character) is used between two ranges that do not overlap. To fix this error double check that the ranges referenced in the formula that use the intersection operator actually have cells in common.
#SPILL error - The #SPILL! error occurs only in version Excel 365 and is caused by a dynamic array being to large, meaning there are cells below and/or to the right that are not empty. This prevents the dynamic array formula expanding into new empty cells.
#DIV/0 error - This error happens if you try to divide a number by 0 (zero) or a value that equates to zero which is not possible mathematically.
#VALUE error - The #VALUE error occurs when a formula has a value that is of the wrong data type. Such as text where a number is expected or when dates are evaluated as text.
#REF error - The #REF error happens when a cell reference is invalid. This can happen if a cell is deleted that is referenced by a formula.
#NAME error - The #NAME error happens if you misspelled a function or a named range.
#NUM error - The #NUM error shows up when you try to use invalid numeric values in formulas, like square root of a negative number.
#N/A error - The #N/A error happens when a value is not available for a formula or found in a given cell range, for example in the VLOOKUP or MATCH functions.
#GETTING_DATA error - The #GETTING_DATA error shows while external sources are loading, this can indicate a delay in fetching the data or that the external source is unavailable right now.
7.2 The formula returns an unexpected value
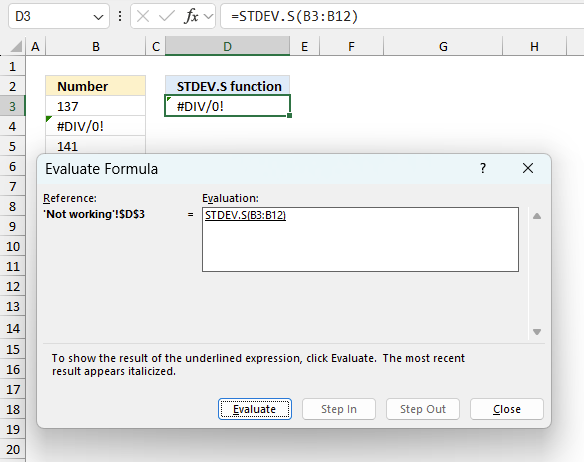
To understand why a formula returns an unexpected value we need to examine the calculations steps in detail. Luckily, Excel has a tool that is really handy in these situations. Here is how to troubleshoot a formula:
- Select the cell containing the formula you want to examine in detail.
- Go to tab “Formulas” on the ribbon.
- Press with left mouse button on "Evaluate Formula" button. A dialog box appears.
The formula appears in a white field inside the dialog box. Underlined expressions are calculations being processed in the next step. The italicized expression is the most recent result. The buttons at the bottom of the dialog box allows you to evaluate the formula in smaller calculations which you control. - Press with left mouse button on the "Evaluate" button located at the bottom of the dialog box to process the underlined expression.
- Repeat pressing the "Evaluate" button until you have seen all calculations step by step. This allows you to examine the formula in greater detail and hopefully find the culprit.
- Press "Close" button to dismiss the dialog box.
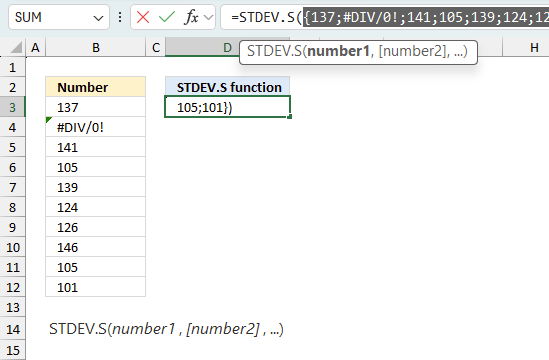
There is also another way to debug formulas using the function key F9. F9 is especially useful if you have a feeling that a specific part of the formula is the issue, this makes it faster than the "Evaluate Formula" tool since you don't need to go through all calculations to find the issue..
- Enter Edit mode: Double-press with left mouse button on the cell or press F2 to enter Edit mode for the formula.
- Select part of the formula: Highlight the specific part of the formula you want to evaluate. You can select and evaluate any part of the formula that could work as a standalone formula.
- Press F9: This will calculate and display the result of just that selected portion.
- Evaluate step-by-step: You can select and evaluate different parts of the formula to see intermediate results.
- Check for errors: This allows you to pinpoint which part of a complex formula may be causing an error.
The image above shows cell reference B3:B12 converted to hard-coded value using the F9 key. The STDEV.S function requires non-error values which is not the case in this example. We have found what is wrong with the formula.
Tips!
- View actual values: Selecting a cell reference and pressing F9 will show the actual values in those cells.
- Exit safely: Press Esc to exit Edit mode without changing the formula. Don't press Enter, as that would replace the formula part with the calculated value.
- Full recalculation: Pressing F9 outside of Edit mode will recalculate all formulas in the workbook.
Remember to be careful not to accidentally overwrite parts of your formula when using F9. Always exit with Esc rather than Enter to preserve the original formula. However, if you make a mistake overwriting the formula it is not the end of the world. You can “undo” the action by pressing keyboard shortcut keys CTRL + z or pressing the “Undo” button
7.3 Other errors
Floating-point arithmetic may give inaccurate results in Excel - Article
Floating-point errors are usually very small, often beyond the 15th decimal place, and in most cases don't affect calculations significantly.
Functions in 'Statistical' category
The STDEV.S function function is one of 73 functions in the 'Statistical' category.
How to comment
How to add a formula to your comment
<code>Insert your formula here.</code>
Convert less than and larger than signs
Use html character entities instead of less than and larger than signs.
< becomes < and > becomes >
How to add VBA code to your comment
[vb 1="vbnet" language=","]
Put your VBA code here.
[/vb]
How to add a picture to your comment:
Upload picture to postimage.org or imgur
Paste image link to your comment.
Contact Oscar
You can contact me through this contact form